=======================================================================
Cybernetics in the 3rd Millennium (C3M) Volume 12 Number 2, Dec. 2015
Alan B. Scrivener — www.well.com/user/abs — mailto:abs@well.com
========================================================================
 "big data" illustration from Datanami article
(www.datanami.com/2014/09/08/survey-big-data-deployments-reaching-tipping-point)
In this issue:
"big data" illustration from Datanami article
(www.datanami.com/2014/09/08/survey-big-data-deployments-reaching-tipping-point)
In this issue:
Short Subjects
 "short subjects" film card
(columbiashortsdept.weebly.com/selected-short-subjects.html)
"short subjects" film card
(columbiashortsdept.weebly.com/selected-short-subjects.html)
- An Interesting Article
I once read an essay on the etymology of the word "cybernetics" which was
actually an introduction to a book on the topic, What is Cybernetics
(1959) by Georges Théodule Guilbaud, which pointed out that though the
word was a neologism in English as of about 1946, its French equivalent,
cybernetique, had been coined by André-Marie Ampère
(for whom the amp is named) to describe the science of government
in 1834.
( en.wikipedia.org/wiki/Cybernetics )
Typically the origin of the word cybernetics is given as kybernētēs, the Greek word for
steersman. I don't know about you but I've never heard anyone use the word steersman
anywhere except an article on the origin of the word cybernetics. I prefer to tell people
that it means pilot, since that's what we usually call the person who steers a craft.
I recently found a two-year-old article on io9.com that doesn't go back that far, but
deals with some of the twists and turns since Norbert Wiener introduced it into English.
The Bizarre Evolution of the Word "Cyber" by Annalee Newitz
( io9.com/today-cyber-means-war-but-back-in-the-1990s-it-mean-1325671487 )
begins by saying:
Today, cyber means war. But back in the 1990s, it meant sex — at least, the kind of sex you
can have in a chat room. Why did the word change, and where did it originally come from?
- System Sciences Facebook group
I recently joined a group on Facebook called "System Sciences" which has had
some interesting postings. The was a dust-up recently over a misguided attempt
to rename the group, and the problem of people using systems science to justify
their own politics never goes away (I know I'm guilty of it), but overall it's
worth the mindshare I give it.
( www.facebook.com/groups/2391509563 )
- web-based system dynamics software
I got to thinking recently that the World Wide Web (WWW) had become the new
"platform" for an awful lot of software that used to be deployed on more
traditional operating systems, like Windows, MacOS and UNIX/Linux, so it
seemed likely that system dynamics software — usually used to model
systems with block diagrams and then simulate their behaviors over time and
plot the results as line graphs — might have trended that way as well.
Sure enough a quick Google search found these two offerings:
- INSIGHT maker
( insightmaker.com )
"Create an Insight Maker account to start building models. Insight Maker is completely free."
- iMODELER
( www.consideo.com/imodeler24.html )
Starting at 232.50 Euros/year (approx. $250).
"There is a free educational version of the iMODELER."
Also, since the last time I was paying attention, Wikipedia now offers an
up-to-date guide to system dynamics applications of all kinds.
( en.wikipedia.org/wiki/List_of_system_dynamics_software )
- An Exciting Paper
This is pretty math-geeky but it may have important practical applications
for making systems theory more usable. A new paper was published in the
Journal of the American Statistical Association this year called Accelerating
Asymptotically Exact MCMC for Computationally Intensive Models via Local
Approximations by Patrick R. Conrad, Youssef M. Marzouk, Natesh S. Pillai
and Aaron Smith.
( arxiv.org/pdf/1402.1694v4.pdf )
Science Daily has an article explaining it more-or-less in layman's
terms, using bull's-eyes and Monopoly games as analogies, called "Shrinking
bull's-eye" algorithm speeds up complex modeling from days to hours.
( www.sciencedaily.com/releases/2015/11/151117112646.htm )
It involves some improvements in the efficiency of Markov chain Monte Carlo
MCMC) techniques for exploring the state space of a complex system. Typically,
given the definition of a deterministic system, we want to know where its
basins of attraction are for all of its possible initial conditions and
parameters. In rare cases this can be determined by analysis (in the
French mathematician sense) for certain simple linear systems, or by
inspection in trivial systems, but most of the time it can only be done
by what is called integrating or simulating the system with all
possible initial conditions. Except, if the inputs can be real numbers, the
set of all possible initial conditions is infinite. In this case a sampling
of possible inputs is used, in the hopes that all of the important features
will become obvious. When this is a random sampling, the approach is called
a Monte Carlo method after the famous casino in Monaco.
What Conrad et. al. have done is to find some computation short-cuts that
typically don't interfere with getting the right answer, which will make
these techniques more useful in the future. End users will eventually see
faster solvers (such as the one built in to Excel, as well as commercial
plug-ins) able to deliver solutions more quickly to complex optimization
problems.
- Book review: Antifragile: Things That Gain from Disorder (2014)
by Nassim Nicholas Taleb
( www.amazon.com/exec/obidos/ASIN/0812979680/hip-20 )
I was at Barnes & Noble recently and decided it had been too long since I read
anything by Nassim Nicholas Taleb, so I somewhat randomly picked his Antifragile
to buy. I'm so glad I did. This book is a bit hard to read because Taleb
spends so much ink telling us how smart he is and how stupid everyone else
is, but he ends up connecting an awful lot of dots. Bits of folklore and
old sayings I never thought of as part of a larger pattern suddenly fit
together into a vast unobserved principle of survival. For example:
- if you shake a young tree it grows up stronger
- having an unreliable income better prepares you for financial hardship
- during a hospital strike the death rate goes down
- eating the same thing every day is bad for you
- living with domesticated animals and their diseases gave Europeans
stronger immune systems
- betting (or investing) a small amount of your savings on extreme
market volatility can be very lucrative in the long run
Taleb asked a number of people what the opposite of "fragile" is, and
got answers like "robust." But he points out that if fragile means harmed
by disruption, robust is unharmed by disruption. Farther along the opposite
scale we have a state of being helped by disruption, which there was no word
for, so he coined "antifragile."
In addition to explaining a lot of things, this book helped me survive and
thrive during a period of financial hardship earlier this year.
- Books I Haven't Read
The following books have showed up on my radar but I don't review books I haven't read yet:
- Key Business Analytics: The 60+ Business Analysis Tools Every
Manager Needs To Know (2016) by Bernard Marr
( www.amazon.com/exec/obidos/ASIN/1292017430/hip-20 )
This book coming out next March is by the guy who wrote the Forbes
article on Dickey's BBQ and Big Data (below). Looks
interesting.
- The No Breakfast Fallacy: Why the Club of Rome was wrong about us running out of
minerals and metals (2015) by Tim Worstall
( www.amazon.com/exec/obidos/ASIN/B00YHTIMHS/hip-20 )
Short form of the analogy: you can't determine we're going to run out of
breakfasts just by looking in the 'fridge. I'm always eager to see more
debate on the Limits to Growth models.
- Systems Thinking Made Simple: New Hope for Solving Wicked Problems (2015)
by Derek Cabrera and Laura Cabrera
( www.amazon.com/exec/obidos/ASIN/0996349308/hip-20 )
Cute title. The layout looks simple and clear. I'm intrigued.
- Visual Complexity: Mapping Patterns of Information (2013)
by Manuel Lima
( www.amazon.com/exec/obidos/ASIN/1616892196/hip-20 )
From the Amazon blurb: "This groundbreaking 2011 book — the first to combine a
thorough history of information visualization with a detailed look at today's most
innovative applications — clearly illustrates why making meaningful connections
inside complex data networks has emerged as one of the biggest challenges in
twenty-first-century design. From diagramming networks of friends on Facebook
to depicting interactions among proteins in a human cell, Visual Complexity
presents one hundred of the most interesting examples of information
visualization by the field's leading practitioners."
Most visualizations techniques don't scale well. This book seems to provide hope.
- Visual Computing (2000)
by Richard Mark Friedhoff and Mark S. Peercy
I've admired Friedhoff's psychology of perception research for a while, from
his writings and personal contact. He was also the first person to invite me
to speak at a conference, for which I am still grateful. I'm eager to see what
he and his co-author have to say about this somewhat neglected field.
( www.amazon.com/exec/obidos/ASIN/0716750597/hip-20 )
- Perspectives of Nonlinear Dynamics, Vol. 1 (1992)
by E. Atlee Jackson
( www.amazon.com/exec/obidos/ASIN/0521426324/hip-20 )
Nonlinear Dynamics is notoriously hard to understand and to explain,
so I'm always looking for better books about it.
- Notes on the Synthesis of Form (1964) by Christopher Alexander
( www.amazon.com/exec/obidos/ASIN/0674627512/hip-20 )
I have long praised Alexander's architecture books A Pattern Language
(1977) and A Timeless Way of Building (1979), which also inspired the
software patterns movement, but I didn't make the connection until earlier this
year that he also wrote this classic, praised by the Whole Earth Catalog
in the 1970s. All this came to light when I found my good friend Mike P. was a
student of Alexander's, while conversing about a vast array of topics at his
cabin on Palomar Mountain.
A Small Essay On Big Data
 illustration of data mining
( www.wecatchfraud.com/blog/data-mining-for-fraud )
illustration of data mining
( www.wecatchfraud.com/blog/data-mining-for-fraud )
A little boy bullies his grandfather into getting him a bicycle for his
birthday a month early. An older woman gets in a car accident and vows never
to drive again and buys a bicycle. At the bicycle shop the merchant writes
down what was sold when and for how much, but not why. A statistician
accumulates all this data and then studies it to figure out why people buy
bicycles. The statistician says, "It doesn't matter," and it doesn't to them...
— Gregory Bateson lecture at Kresge college, 14 October 1977 (paraphrased)
There has been a lot of ink lately about this newfangled thing called "big
data" and I'd like to shed some light on it. We can break it down into two
parts:
- big
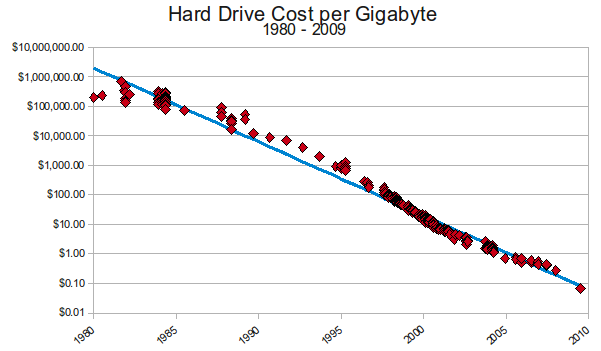 hard drive cost per gigabyte 1980-2009
( www.mkomo.com/cost-per-gigabyte )
In computers "big" is definitely a relative term, and time-based as well.
What was big three years ago often isn't so big now.
I remember in the early 1980s I read a story in the computer press (I think it
was Information Week) about a blues and jazz fan who had collected a
vast amount of data on phonograph records of blues and jazz, including every
artist who performed on every song. It covered most of the records ever
pressed, and was all typed on 3x5 file cards. At one point he offered to
donate his data to Compuserve, the biggest on-line community at the time
which people connected to using dial-up modems. They declined, because they
couldn't afford the disk space to host it. Because the data was text only,
it's hard to imagine it amounted to more than maybe 10 megabytes, but as the
above graph shows, at that time it would've cost upwards of $100,000 just for
the disk hardware.
The last disk drive I bought, about a year ago, held a terabyte (one trillion
bytes) and cost about $80. At the time I was telling friends that as a young
man I never dreamed I'd ever own a trillion of anything.
Today when we talk about "big" data we can marvel over the fact that Google
allegedly keeps the entire text of the internet in main memory (not disk)
in a huge cluster of servers. But it won't be long before that doesn't seem
so big.
So, in the context of today's tech headlines, it's fair to say that data is
"big" if it's bigger than we're used to dealing with.
hard drive cost per gigabyte 1980-2009
( www.mkomo.com/cost-per-gigabyte )
In computers "big" is definitely a relative term, and time-based as well.
What was big three years ago often isn't so big now.
I remember in the early 1980s I read a story in the computer press (I think it
was Information Week) about a blues and jazz fan who had collected a
vast amount of data on phonograph records of blues and jazz, including every
artist who performed on every song. It covered most of the records ever
pressed, and was all typed on 3x5 file cards. At one point he offered to
donate his data to Compuserve, the biggest on-line community at the time
which people connected to using dial-up modems. They declined, because they
couldn't afford the disk space to host it. Because the data was text only,
it's hard to imagine it amounted to more than maybe 10 megabytes, but as the
above graph shows, at that time it would've cost upwards of $100,000 just for
the disk hardware.
The last disk drive I bought, about a year ago, held a terabyte (one trillion
bytes) and cost about $80. At the time I was telling friends that as a young
man I never dreamed I'd ever own a trillion of anything.
Today when we talk about "big" data we can marvel over the fact that Google
allegedly keeps the entire text of the internet in main memory (not disk)
in a huge cluster of servers. But it won't be long before that doesn't seem
so big.
So, in the context of today's tech headlines, it's fair to say that data is
"big" if it's bigger than we're used to dealing with.
- data
Big businesses have been collecting data about their customers on computers
since the 1960s, and some small businesses have been at it since the 1980s.
What is fairly new is that they are finally studying their data intently
to see how much they can learn from it. Of course, extracting meaning
from data has been going on all along: they used to call it Management
Information Systems (MIS), and now they call it analytics.
We've also seen the terms data mining, data warehousing,
and On-Line Analytical Processing (OLAP).
When I worked for a web store software vendor in the late 1990s I was
alarmed that the marketing department added a box to the architecture
diagram in the marketing literature that said "analytics." I whispered
to the vice president of marketing after a presentation, "that piece doesn't
exists — what happens if we sell it?" He assured me he knew what he
was doing. It tuned out he did. Just about every time we gave a presentation
using that diagram, a prospect would say, "We're glad you have that module,
because we're going to need it later." Always later.
Well, later finally became now in the last ten years or so, and when companies
began to see the tech giants like Google making real money from analytics they
decided it was time to get serious.
A CASE STUDY
 Dickey's Barbecue Pit signage
( charlotterestauranttraffic.com/ballantyne/dickeys-barbecue-pit-coming-to-ballantyne )
Dickey's Barbecue Pit signage
( charlotterestauranttraffic.com/ballantyne/dickeys-barbecue-pit-coming-to-ballantyne )
This year I was delighted that a barbecue chain called Dickey's opened a store
down the street from me in the mountain community where I live. They are
headquartered in Texas, and I'd sampled their wares and enjoyed them on a
business trip to Dunn Loring, Virginia. While reading some promotional material
on their web site,
(
www.dickeys.com )
I was surprised to discover that they've just this year rolled out a big data
solution, and have been generous to share a lot of details in the tech press
and elsewhere, so I'm going to use them to illustrate some important concepts.
Here are the articles:
- They have the article on their own website which gave me my first
clue, "Dickey's Barbecue Pit Gains Operational Insight across 500
Stores with Advanced Big Data Analytics in the Cloud"
( www.dickeys.com/news/2015/05/29/dickeys-barbecue-pit-gains-operational-insight-across-500-stores-with-advanced-big-data-analytics-in-the-cloud )
- They've also permitted one of their vendors, Syncsort, to talk
about the deployment on their own blog, in an article called "Barbecue & Big
Data: Dickey's Journey into Analytics in the Cloud" by Nick Larsen.
(I love it when tech customers do this; so often they are secretive to the
point of paranoia, which really hampers the poor vendor in getting more sales).
( blog.syncsort.com/2015/06/barbecue-and-big-data )
- Forbes has an article called "Big Data At Dickey's Barbecue Pit: How
Analytics Drives Restaurant Performance" by Bernard Marr.
( www.forbes.com/sites/bernardmarr/2015/06/02/big-data-at-dickeys-barbecue-pit-how-analytics-drives-restaurant-performance )
- Fast Casual has an article called "Tech in a box: How Dickey's
uses big data to target marketing strategies" by Cherryh Cansler.
( www.fastcasual.com/articles/tech-in-a-box-how-dickeys-uses-big-data-to-target-marketing )
- There's also a Wall Street Journal article behind a paywall.
( blogs.wsj.com/cio/2015/05/28/dickeys-barbecue-looks-to-cloud-for-edge-against-competitors-like-chipotle )
IMPORTANT COMPONENTS
The following important components are present in a well-thought-out "big
data" deployment, and help differentiate it from earlier data analytics
initiatives:
- asking useful questions
It's important to have specific changes you are able to make in a business,
and to ask questions based on these factors. Sometimes people just want to
see what they can find by just "poking around" in data. This isn't
necessarily a bad thing, especially in an early experimental phase; I've
certainly done it myself. But soon you have to get mission-specific.
- no more sampling
In the old days analytics was often done by sampling data, since it was
perceived as impossible to crunch every number available. As a result
a lot of effort was spent making sure the samples were representative.
Now that it is possible to have a computer process all of the available data,
the sampling problem has gone away. By trading off completeness for quality,
the new challenge is to make sure that "bad data" is a small portion of the whole.
- "best of breed"
I believe the Gartner Group coined the term "best of breed" in the 1990s
to describe companies cobbling together tools from different vendors,
using the pieces deemed the best for each sub-task, as a way to convince
buyers not to get "all-in-one" solutions from big companies like IBM
and Oracle. We are seeing this today with big data deployments, such as
Dickey's "Smoke Stack" (their name) system:
Business intelligence and data warehouse solutions provider iOLAP combined
Syncsort's DMX data integration software with Yellowfin's [Business
Intelligence] platform and Amazon Redshift [servers] for data warehousing to
create Smoke Stack and implement it across Dickey's more than 500 locations.
— Fast Casual (4)
- data fusion
The term "data fusion" refers to combining data from multiple sources into one
report or visualization. Dickey's had this problem in several ways: in
combining customer feedback with Point of Sale (POS) data, bus also in
combining POS data from different systems rolled out to different locations
at different times.
These days the "NoSQL" database is popular (the No stands for "not only") to
combine sources that accept the long-used Structured Query Language (SQL) with
those that don't. The traditional approach was to stuff other data, such as
log files and emails, into a SQL database and then query it. This is what
"data warehousing" was originally for. But both speed and size constraints
are making that less practical. Vendors like SQLStream and X15 are making it
easier to use SQL on sources not designed for it. But most of the time folks
are just kludging together solutions; that's how the consultants make a lot
of their money.
[CIO] Laura [Rea Dickey] explains: "It's biggest end user benefit is bringing
together all of our different data sets from all of our source data – whether
it's our POS system in stores directly capturing sales as they happen, or a
completely different source such as a customer response program, where folks
are giving us feedback online or in different survey formats."
— Fast Casual (4)
- speed
In the mainframes managers would sometimes wait for months for reports,
by which time they were long obsolete. During the 1990s dot-com era folks
were usually getting weekly reports, and considered them fast if they got them
daily. Today they don't want to wait an hour. Dickey's likes to notice
before lunch hour is over if they are selling fewer ribs than normal (which
take many hours to smoke), so they can responding with texting
coupons to customers in time to boost lunch sales.
This is why big data processes and work-flow must be fully automated, after
initial experiments are done to determine what variables to track and how to
report results — there just isn't time for human intervention any more!
All of the data is examined every 20 minutes to enable immediate decisions, as
well as during a daily morning briefing at corporate HQ, where higher level
strategies can be planned and executed.
— Forbes (3)
- usability
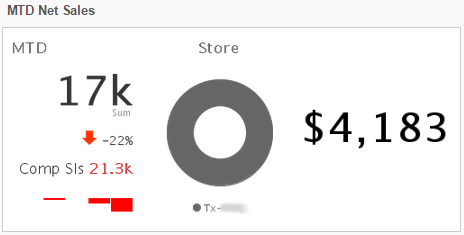 Dickey's Barbecue business dashboard (Syncsort)
Another important feature of modern bi data deployments is the high usability.
Totally computer illiterate employees are getting rarer, but many only have
experience with smart phones. Business dashboards running on tablets, such as
the iPad, are now the tool of choice for keeping field employees updated on
business stats.
Dickey's Barbecue business dashboard (Syncsort)
Another important feature of modern bi data deployments is the high usability.
Totally computer illiterate employees are getting rarer, but many only have
experience with smart phones. Business dashboards running on tablets, such as
the iPad, are now the tool of choice for keeping field employees updated on
business stats.
Using tablets to enhance the customer experience isn't new, but Dickey's
Barbecue Restaurants is putting them in the hands of its c-level executives
and staff as opposed to only its customers, said Paula Suarez, director of
software analysis and development for Dickey's Barbecue Restaurants, a
franchise with more than 500 units.
During the Monday session, "Tablets: When, Where, Why and How" at the ICX
Summit in Chicago, Suarez shared the company's custom-developed business
intelligence service called Smoke Stack that analyzes data to help the
restaurant connect with customers, which leads to sales increases.
Specifically, the platform collects info from the chain's POS, loyalty
programs, customer surveys, marketing promos and inventory systems to provide
near real-time feedback on sales and other key performance indicators, Suarez
said.
The "technology in a box," as Suarez described it, was born out of the
franchise's need for fast information since it's been expanding so quickly
over the past couple years.
— Fast Casual (4)
- data cleansing
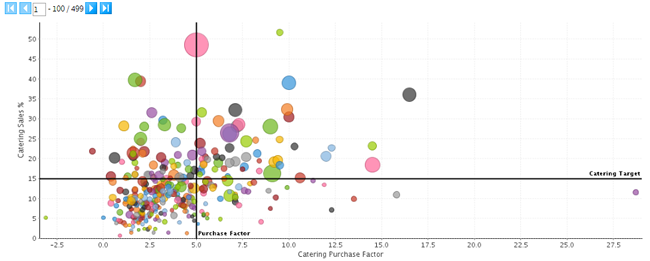 scatter chart of Dickey's BBQ sales vs. catering purchases
( blog.syncsort.com/2015/06/barbecue-and-big-data )
Before "starting the engine" and running fully automated reports, Dickey's had
to make sure what was coming out of their POS systems was reliable. Some
hand-crafted data analysis and visualization helped accomplish this. As the
above scatter chart comparing sales with catering purchase shows:
scatter chart of Dickey's BBQ sales vs. catering purchases
( blog.syncsort.com/2015/06/barbecue-and-big-data )
Before "starting the engine" and running fully automated reports, Dickey's had
to make sure what was coming out of their POS systems was reliable. Some
hand-crafted data analysis and visualization helped accomplish this. As the
above scatter chart comparing sales with catering purchase shows:
[This] illustrates possible
compliance issues with stores either purchasing off program or not using the
POS to capture catering sales.
— Syncsort (2)
- arithmetic
Some folks a wary of big data because they think the math will be hard.
Actually, a lot of it is stuff you'd learned by the third grade: simple
arithmetic. After whatever jiggery-pokery is needed to get numbers ("how
many orders are placed between midnight and dawn by single parents?") they
are usually just added, and occasionally divided by a total number of events
to get an average.
- AI/machine learning
But then the math jumps from trivial to impenetrable. Advanced statistics,
machine learning, and borderline Artificial Intelligence (AI) are sometimes
employed to find subtle patterns, and often they are used by folks who don't
really know how they work. Proceed with caution.
- efficiency
What makes some big data math tricky is the need to do it very quickly on very
large sets of very large numbers. This is where clusters of blade servers and
parallel languages like Hadoop get invoked. There used to be a joke that the
weather serice could use supercomputers to predict tomorrow's weather, but
it took three days. Nowadays we are solving this sort of problem, and creating
a new job description for big data cloud programmers.
- results
As a result of the Smoke Stack system, Dickey's is learning a lot more about
their customers. Note that a lot of this stuff would have been virtually
impossible to intuit, or guess, and they wouldn't have known if they were
right anyway.
What Dickey's learned
Suarez said the customer info she's collected is priceless. For example, a few
things the platform has already taught her have included:
- The chain's average lunch guest is male, 43, drives an SUV and commutes
30 minutes to work, so the chain now considers Ford finance customers who live
15 to 30 minutes away from a Dickey's as a prime advertising target.
- That women with kids usually visit Dickey's for a later and longer lunch
on Wednesdays and that these ladies use Pinterest. To capitalize on this,
Dickey's rolled out a Pinterest campaign in which it introduces a craft each
Wednesday.
- And that one of the strongest commonalities among guests is that they
play fantasy football and have dogs. This means the chain spends more money on
advertising on fantasy football sites than on back-to-school campaigns, for
example, and may run commercials on Animal Planet to reach their target
audience. They also include dogs in catering photos to inspire dog-loving
consumers to notice their ads.
— Fast Casual (4)
ETHICAL CONSIDERATIONS AND PITFALLS
A power so great it can only be used for good or evil!
— The Tale of the Giant Rat of Sumatra (audio comedy 1974)
The Firesign Theatre
( www.amazon.com/exec/obidos/ASIN/B00006BNDR`/hip-20 )
It seems like the two main concerns about all this data anylitics going on is
that it will be too effective or not effective enough.
I used to use the analogy that Sam Drucker at the general store (in the TV
shows
Petticoat Junction and
Green Acres) knew who bought what
when, and could use this information any way he saw fit — as long as he
didn't gossip.
But this article on the Socialist Origins of Big Data from The New Yorker
reminded me that the nanny state is greedy for our data so they can socially
engineer us.
The Planning Machine: Project Cybersyn and the origins of the Big Data nation.
(
www.newyorker.com/magazine/2014/10/13/planning-machine )
Political action is the tool I see for citizens to keep the government from
meddling too much in our lives.
When it comes to commerce, I see the picture as less sinister because the
interactions are voluntary (usually) and we can retaliate with boycotts and
shaming, especially on social media and Yelp. But we must remain vigilant.
Two big pitfalls with big data techniques are that we usually don't know
why things work, and we never know if they will stop working. The "Big Data"
book listed above tells the story of how Google searches for certain terms
was far faster at detecting flu epidemics than traditional approaches such
as monitoring ER admissions. But then over time it became less effective
for reasons that remain unclear.
Again, vigilance must be the answer, among end users and among businesses.
FURTHER STUDY
- Big Data: A Revolution That Will Transform How We Live, Work, and Think (2014)
by Viktor Mayer-Schönberger and Kenneth Cukier
( www.amazon.com/exec/obidos/ASIN/0544227751/hip-20 )
This book basically sells the concept and what it can do for you.
- Keeping Up with the Quants: Your Guide to Understanding and Using Analytics (2013)
by Thomas H. Davenport and Jinho Kim
( www.amazon.com/exec/obidos/ASIN/142218725X/hip-20 )
This is a nuts and bolts guide for the business person who is going to
hire employees or consultants to do analytics, letting them know about
the work the business has to do to be ready.
- Amazon's Cloud Monopoly
( www.cringely.com/2015/11/02/amazons-cloud-monopoly )
This article offers proof that Amazon owns the small-to-medium business
cloud computing space.
PROGRAMMING BIG DATA: BABY STEPS
Several blogs have reported that business owners are afraid of Big Data
initiatives because they think it will cost a whole lot of money. If you
are a programmer for such a business I suggest proposing small pilot
programs taking "baby steps" to determine the value of these efforts.
You do need to prepare management for the fact that they will ultimately need
an Information Technology (IT) department (or consultants, or a services
company under contract) plus an Analytics department (or consultants, or a
services company under contract). But it is possible to start small.
One of the most labor-intensive tasks in analyzing data from the real world,
especially user input from the web, is
data cleansing, which
is the cyber equivalent of removing nails before sawing boards.
This is one reason I always like to test with real world data. For some
time if I needed to process addresses, I would grab data from "maps to
the movie stars' homes" websites. It gives you data with weird anomalies
like multiple word street names, addresses without numbers, and it used to
included funny characters. Unfortunately the suburbs of Los Angeles
County seemed to have all gone to great lengths to remove punctuation
marks from street names, such as tildes, accents, umlauts, etc. (One
consequence of this is that the famous Cañon Drive in Beverly Hills
is now Canon Drive, and mispronounced accordingly by all but the old
times.) So be sure to put the funny characters back in.
Two books in the "pragmatic programmer" series have useful tips for
dealing with data:
The other big labor sink is dealing with large number arithmetic. There are
several tools to help with this:
- If you are coding in a strongly typed language like C, C++ or Java, it may
pay to find and use a "bignum" library. But if all you are doing is adding
large numbers, the algorithms are quite simple. Consider the following code
example (written in Python for ease of data type handling, but easily
translated into other languages.) The assumption is that a program in a
strongly-typed language is counting things, and when it gets close to the
integer limit (2,147,483,647 for a 32 bit integer or 9,223,372,036,854,775,807
for a 64 bit integer) the number is handed off to a utility that adds it to a
total already in a disk file as a string of digits. This is a template for
that utility. For testing I used a file of one followed by a hundred zeros,
i.e. 10 to the 100th power (10^100 in some languages), the number called
"google" after which the (misspelled) search company was named. Since there
are only an estimated 10^82 atoms in the universe, this is probably big enough
for anything an Earth-based business is going to count (unless they are
counting hypothetical combinations of things).
| test_file.txt
10000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
|
This is the source code that adds an integer value to this file.
| # python
increment_out_of_core.py
#
# increment_out_of_core.py
#
# CREATED: 2015.06.07 ABS from scratch
# MODIFIED: 2015.06.08 ABS debugged
#
def increment_out_of_core(add_int, filename, verbose):
#
add_str = str(add_int)
#
# read input file and strip newline
#
fi = open(filename, 'rU')
input_str = fi.readline()
stripped_str = input_str.rstrip('\n')
#
# confirm input file and parameter
#
if verbose:
print 'verbose: stripped input string: {0}'.format(stripped_str)
print 'verbose: add int: {0}'.format(add_int)
print 'verbose: digits filename: {0}'.format(filename)
#
# validate -- stripped input_str must be only digits
#
line_count = len(file('test_file.txt', 'r').readlines())
if verbose:
print 'verbose: lines in file: {0}'.format(line_count)
if not line_count == 1:
print("error: input file isn't one line")
quit()
if not stripped_str.isdigit():
print("error: input string has non-digit")
quit()
#
# open output file
#
fi.close()
fo = open(filename, 'w')
#
# copy input to output adding
#
len_i = len(stripped_str)
len_a = len(add_str)
carry = 0
backwards_output_str = ""
for col in range (0, len_i):
reverse_col_i = len_i - col - 1
reverse_col_a = len_a - col - 1
input_digit = stripped_str[reverse_col_i]
if reverse_col_a < 0:
add_digit = 0
else:
add_digit = add_str[reverse_col_a]
result_int = int(input_digit) + int(add_digit) + carry
carry = 0
if result_int > 9:
carry = 1
result_int = result_int - 10
backwards_output_str = backwards_output_str + str(result_int)
if verbose:
print 'verbose: col: {0} reverse_col_i: {1} input_digit: {2} \
add_digit: {3} carry: {4} result: {5}'.format(col, \
reverse_col_i, input_digit, add_digit, carry, result_int)
if carry==1:
backwards_output_str = backwards_output_str + "1"
#
# reverse output
#
output_str = backwards_output_str[::-1]
output_str = output_str + "\n"
#
# write output file
#
fo.write(output_str)
#
# parse args
#
from optparse import OptionParser
parser = OptionParser()
parser.add_option("-v", "--verbose",
action="store_true", dest="verbose", default=False,
help="verbose mode")
parser.add_option("-a", "--add", dest="add_int", action="store", type="int",
help="set add amount", default=1)
parser.add_option("-f", "--filename", dest="digits_filename", action="store",
help="set filename of digits to increment",
default="test_file.txt")
(options, args) = parser.parse_args()
#
increment_out_of_core(options.add_int, options.digits_filename, options.verbose)
|
You can run this in a shell on a system with Python installed by pasting the
text into file named increment_out_of_core.py and then typing:
| python increment_out_of_core.py
|
- In Python version 2.5 and up there is a built in bignum feature, as this
example shows(user input in red):
| # python
Python 2.7.3 (v2.7.3:70274d53c1dd, Apr 9 2012, 20:52:43)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> pow(10,100)-1
10000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001L
>>>
|
- the UNIX/Linux basic calculator (bc) program (installed on Mac OS X and
available from gnu.com for Windows) also handles big nums (user input in pink):
| # bc
bc 1.06
Copyright 1991-1994, 1997, 1998, 2000 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
10^100+1
100000000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000001
|
The C library function system() (and others like it in different languages)
can be used to pass inputs to a program like bc.
- The Wolfram Alpha web site and mobile app will also accept bignums,
and though it is inconvention to use them as part of an automatic production
work-flow, they are handy for manually confirming test values:
- If you're going to crunch a large number of large numbers, sooner or
later you will need a massively parallel environment like the Hadoop ecosystem,
The book Hadoop in Action (2010) by Chuck Lam
( www.amazon.com/exec/obidos/ASIN/1935182196/hip-20 )
is a good introduction. Bear in mind that surveys show most business owners
fear Hadoop because it sounds like the most expensive solution of all. It
may be if you're going to build or buy racks of blade servers to run it,
and install and maintain it yourselves (even though the software can be free),
but the affordable way to take baby steps is by hosting in the Amazon Web
Services (AWS) cloud environment.
A lot of what people use Hadoop for is just adding large numbers, but in a
massively parallel environment even such a simple operation is tricky and
subtle.
- For more info on hosting Hadoop and its alternatives on AWS, see this
article: Big Data Analytics Options on AWS Erik Swensson, December 2014
( d0.awsstatic.com/whitepapers/Big_Data_Analytics_Options_on_AWS.pdf )
Good luck!
Note Re:
"If It's Just a Virtual Actor,
Then Why Am I Feeling Real Emotions?"

Part seven of this serialization will appear next time.
========================================================================
newsletter archives:
www.well.com/user/abs/Cyb/archive
========================================================================
Privacy Promise: Your email address will never be sold or given to
others. You will receive only the e-Zine C3M from me, Alan Scrivener,
at most once per month. It may contain commercial offers from me.
To cancel the e-Zine send the subject line "unsubscribe" to me.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
I receive a commission on everything you purchase from Amazon.com after
following one of my links, which helps to support my research.
========================================================================
Copyright 2015 by Alan B. Scrivener
Last update:
Wed Dec 2 14:15:26 PST 2015